 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternally Referenced Low-Light Enhancement
May 27, 2026Self-supervised low-light image enhancement (LLIE) is highly appealing as it eliminates the reliance on external paired data. However, the lack of external references causes networks to struggle with decoupling entangled illumination, delicate textures, and amplified noise. To resolve this challenge, we propose an Internally Referenced LLIE framework that extracts reliable physical and structural references from the degraded input image itself. First, we introduce a local exposure-simulated scheme to extract a low-frequency pseudo ground-truth. This serves as an internal physical reference to guide global illumination estimation and correct color casts. Second, we propose a dual-domain preservation strategy with spatial and spectral constraints to construct internal structural references. Specifically, an Illumination-Aligned Perceptual loss preserves global structures under illumination shifts, while a Shift-Invariant Spectral Correlation loss captures fine-grained local structures and suppresses high-frequency noise. Finally, we propose a Gain-Adaptive Feature Modulation (GAFM) mechanism to address highly spatially-variant residual noise. By transforming the self-estimated illumination map into an internal spatial gain prior, GAFM dynamically guides a blind-spot network for spatially-aware denoising. Extensive experiments demonstrate that our method achieves state-of-the-art performance, delivering superior noise suppression and textural fidelity. Code will be publicly released at https://visonj.github.io/IRLE/.
Representative Attention For Vision Transformers
May 14, 2026Linear attention has emerged as a promising direction for scaling Vision Transformers beyond the quadratic cost of dense self-attention. A prevalent strategy is to compress spatial tokens into a compact set of intermediate proxies that mediate global information exchange. However, existing methods typically derive these proxy tokens from predefined spatial layouts, causing token compression to remain anchored to image coordinates rather than the semantic organization of visual content. To overcome this limitation, we propose Representative Attention (RPAttention), a linear global attention mechanism that performs token compression directly in representation space. Instead of constructing intermediate tokens from fixed spatial partitions, it dynamically forms a compact set of learned representative tokens to enable semantically related regions to communicate regardless of their spatial distance, by following a lightweight Gather-Interact-Distribute paradigm. Spatial tokens are first softly gathered into representative tokens through competitive similarity-based routing. The representatives then perform global interaction within a compact latent space, before broadcasting the refined information back to all spatial tokens via query-driven cross-attention. Via replacing coordinate-driven aggregation with representation-driven compression, RPAttention preserves global receptive fields while adaptively aligning token communication with the content structure of each input.RPAttention reduces the dominant token interaction complexity from quadratic to linear scaling with respect to the number of spatial tokens, while maintaining expressive global context modeling. Extensive experiments across diverse vision transformer backbones on image classification, object detection, and semantic segmentation demonstrate the effectiveness of our design.
On the Global Photometric Alignment for Low-Level Vision
Apr 09, 2026Supervised low-level vision models rely on pixel-wise losses against paired references, yet paired training sets exhibit per-pair photometric inconsistency, say, different image pairs demand different global brightness, color, or white-balance mappings. This inconsistency enters through task-intrinsic photometric transfer (e.g., low-light enhancement) or unintended acquisition shifts (e.g., de-raining), and in either case causes an optimization pathology. Standard reconstruction losses allocate disproportionate gradient budget to conflicting per-pair photometric targets, crowding out content restoration. In this paper, we investigate this issue and prove that, under least-squares decomposition, the photometric and structural components of the prediction-target residual are orthogonal, and that the spatially dense photometric component dominates the gradient energy. Motivated by this analysis, we propose Photometric Alignment Loss (PAL). This flexible supervision objective discounts nuisance photometric discrepancy via closed-form affine color alignment while preserving restoration-relevant supervision, requiring only covariance statistics and tiny matrix inversion with negligible overhead. Across 6 tasks, 16 datasets, and 16 architectures, PAL consistently improves metrics and generalization. The implementation is in the appendix.
WiT: Waypoint Diffusion Transformers via Trajectory Conflict Navigation
Mar 16, 2026While recent Flow Matching models avoid the reconstruction bottlenecks of latent autoencoders by operating directly in pixel space, the lack of semantic continuity in the pixel manifold severely intertwines optimal transport paths. This induces severe trajectory conflicts near intersections, yielding sub-optimal solutions. Rather than bypassing this issue via information-lossy latent representations, we directly untangle the pixel-space trajectories by proposing Waypoint Diffusion Transformers (WiT). WiT factorizes the continuous vector field via intermediate semantic waypoints projected from pre-trained vision models. It effectively disentangles the generation trajectories by breaking the optimal transport into prior-to-waypoint and waypoint-to-pixel segments. Specifically, during the iterative denoising process, a lightweight generator dynamically infers these intermediate waypoints from the current noisy state. They then continuously condition the primary diffusion transformer via the Just-Pixel AdaLN mechanism, steering the evolution towards the next state, ultimately yielding the final RGB pixels. Evaluated on ImageNet 256x256, WiT beats strong pixel-space baselines, accelerating JiT training convergence by 2.2x. Code will be publicly released at https://github.com/hainuo-wang/WiT.git.
Anchor then Polish for Low-light Enhancement
Mar 16, 2026Low-light image enhancement is challenging due to entangled degradations, mainly including poor illumination, color shifts, and texture interference. Existing methods often rely on complex architectures to address these issues jointly but may overfit simple physical constraints, leading to global distortions. This work proposes a novel anchor-then-polish (ATP) framework to fundamentally decouple global energy alignment from local detail refinement. First, macro anchoring is customized to (greatly) stabilize luminance distribution and correct color by learning a scene-adaptive projection matrix with merely 12 degrees of freedom, revealing that a simple linear operator can effectively align global energy. The macro anchoring then reduces the task to micro polishing, which further refines details in the wavelet domain and chrominance space under matrix guidance. A constrained luminance update strategy is designed to ensure global consistency while directing the network to concentrate on fine-grained polishing. Extensive experiments on multiple benchmarks show that our method achieves state-of-the-art performance, producing visually natural and quantitatively superior low-light enhancements.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
MODEM: A Morton-Order Degradation Estimation Mechanism for Adverse Weather Image Recovery
May 23, 2025
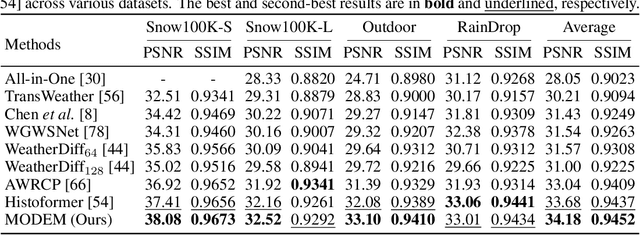
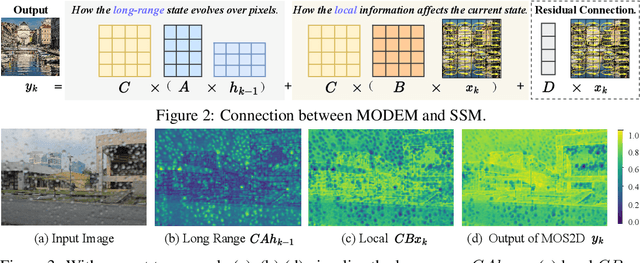
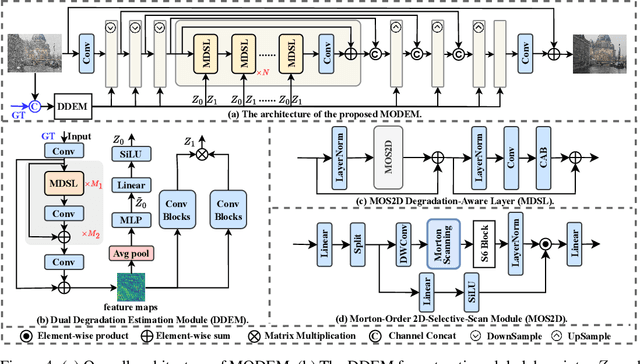
Restoring images degraded by adverse weather remains a significant challenge due to the highly non-uniform and spatially heterogeneous nature of weather-induced artifacts, e.g., fine-grained rain streaks versus widespread haze. Accurately estimating the underlying degradation can intuitively provide restoration models with more targeted and effective guidance, enabling adaptive processing strategies. To this end, we propose a Morton-Order Degradation Estimation Mechanism (MODEM) for adverse weather image restoration. Central to MODEM is the Morton-Order 2D-Selective-Scan Module (MOS2D), which integrates Morton-coded spatial ordering with selective state-space models to capture long-range dependencies while preserving local structural coherence. Complementing MOS2D, we introduce a Dual Degradation Estimation Module (DDEM) that disentangles and estimates both global and local degradation priors. These priors dynamically condition the MOS2D modules, facilitating adaptive and context-aware restoration. Extensive experiments and ablation studies demonstrate that MODEM achieves state-of-the-art results across multiple benchmarks and weather types, highlighting its effectiveness in modeling complex degradation dynamics. Our code will be released at https://github.com/hainuo-wang/MODEM.git.